업무 과정에서 MDB -> SQLite로 마이그레이션 작업을 해야 하는 경우가 생겼습니다.
방법을 찾아 보는 과정에서 ESF Database Migration Toolkit을 알게되었고 비교적 쉽고 간단하게
변경할 수 있어 여러분에게 소개해 드리려고 합니다.
저는 MDB를 SQLite로 변환하였기 때문에 MDB와 SQlite를 기준으로 설명드리겠습니다.
https://www.dbsofts.com/articles/ms_access_to_sqlite/
Migrating data from MS Access to SQLite | DBSofts
Migrating data from MS Access(*.mdb; *.accdb) to SQLite This article will show you how to use a simple database migration wizard to quickly migrate data from MS Access to SQLite! Help you solve complex tasks and save a lot of time! Requirements: Introducti
www.dbsofts.com
위의 사이트에서 먼저 설치를 진행합니다.
요구사항
Windows 7 이상
MS Access 97 이상
SQLite 2 이상


본인의 운영체제 조건에 맞게 32비트 64비트를 선택하여
다운로드를 완료하면 위의 실행파일 아이콘이 생깁니다.
더블클릭하여주시고,
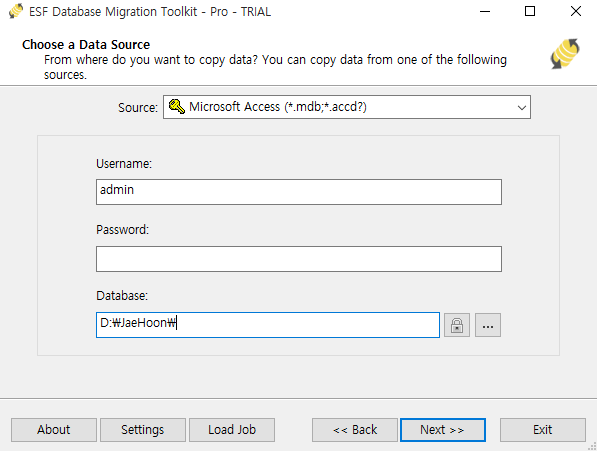
Source에 변경 전 파일 포맷을 눌러주시고, 해당 파일의 경로를 입력하여 줍니다.
이후에 Next를 눌러주시면 됩니다.

Destination에 변경 후 파일 파일 포맷을 눌러주시고, 저장할 경로를
입력해주시고 Next를 눌러주세요

변환 하고자 하는 테이블을 선택하고 Next!

마지막으로 로그를 남길 수 있는 창이 뜹니다.
저는 딱히 로그가 필요하진 않을 것 같아서 공백으로 두었습니다.
그다음 Submit을 눌러주시면 끝!
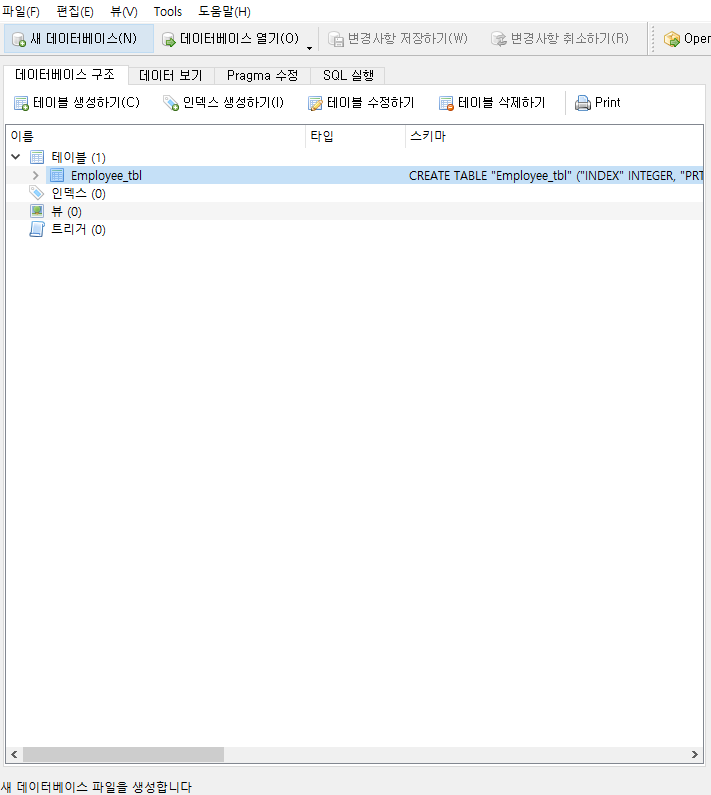
최종적으로 Viewer파일을 통하여 결과를 확인하시면 성공적인 것을 확인할 수 있습니다.
'프로그래밍 > 데이터베이스' 카테고리의 다른 글
| VisualStudio에서 SQLite Database(RDBMS) 사용하기 (0) | 2020.04.10 |
|---|---|
| 데이터베이스(DataBase) 질의어(Query Language) (0) | 2019.04.21 |
| 데이터베이스(DataBase) 관계와 관계타입 (0) | 2019.04.10 |
| [데이터베이스 - 3] ER모델 / 엔티티 / 애트리뷰트 용어 정리 (0) | 2019.03.26 |
| [데이터베이스 - 2] 데이터베이스에 관하여 2 (0) | 2019.02.25 |